When the going gets tough, Camels outlast Unicorns
The Bactrian Camel isn't pretty to the conventional eye. With two oddly large
This blog posts delves into the anonymization and aggregation techniques for mobility data for govtech, smart city, and civic use cases.
Sign up for our webinars to learn from our data scientists and geospatial experts. They will show you how geospatial intelligence can be used in the most cost-effective way to measure and analyze movement patterns.
Geospatial mobility data collected from IoT sensors, mobile devices, beacons, connected cars, fleets, apps, chatbots, and government services is an essential input for civic intelligence to build smarter cities.
CITYDATA is a govtech company that curates fresh, accurate, anonymized, crowdsourced mobility data for 1568 cities and metro areas on a global scale.
Rule #1 in govtech is to protect consumer data and respect privacy. To that end, our team has invested enormous time and resources to research and study the privacy environment, regulations, and cultural expectations in different countries and regions around the world:
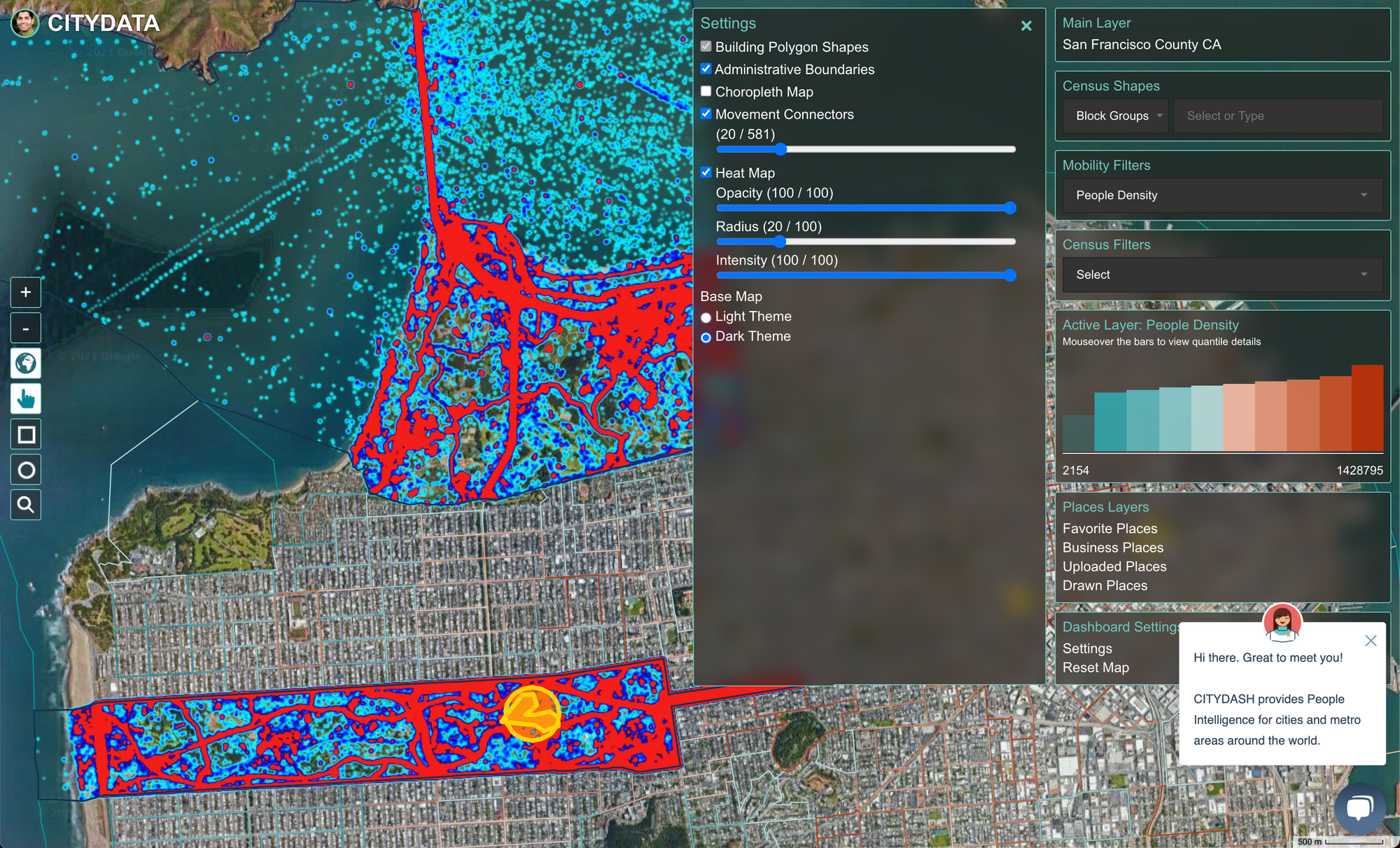
Our analysis of regional law and privacy regulation has informed our data philosophy and technology architecture to make privacy a core tenet in everything we do. Our geospatial data platform incorporates privacy by design, from policy to practice by following the framework principles listed below.
We inform all data suppliers and data sources to never send us personal data or personally identifiable information such as names, email addresses, phone numbers, IMEI numbers, dates of birth, gender, ethnicity, income, transactions, purchase history. That said, when dealing with trillions of data points, if some personal data does make its way to our ingestion endpoint, our data validation algorithms are trained to identify and reject the personal data at source.
We ensure that all unique identifiers are hashed at the ingestion endpoint before storing or archiving the data in our cloud. We use the SHA-1 cryptographic hash function takes the identifier as the input and produces a 160-bit (20-byte) hash value rendered as a hexadecimal number, 40 digits long.
Geospatial data often includes fields like latitude, longitude, and timestamp associated with a an IoT sensor or a mobile device. By spatially and temporally shifting such data using random perturbation within acceptable bounds, we produce an obfuscated dataset without impacting the ability to generate meaningful insights from such data.
It is common to allocate geospatial data to Geohash or H3 grids. We mask the data by aggregating into grid cells and assigning features like device counts, signal counts, density, day-parted counts, weekday counts, hourly ingress-egress to each grid cell. Such grid masking has two-fold benefits because the aggregated features inherently anonymize the underlying data while also making it more convenient to infer patterns across a wider grid.
Anonymizing and aggregating data while maintaining the integrity of the underlying patterns is essential for the safe use of data by municipalities and government entities for civic innovation. Reach out to us if you'd like to access the anonymized and aggregated daily mobility dataset which are useful for inferring people-density, mobility patterns, and trip hops, for 1568 cities and metro areas across 60 countries.
CITYDATA.ai provides pattern-of-life mobility data + Ai for smart cities. CITYDATA knows the answers to the questions “how many people are in your city today” and “what are their movement patterns?”.
CITYDATA offers five main data-as-a-service products:
Founded in 2020 in San Francisco, California, CITYDATA provides fresh, accurate, daily insights that are essential for smart city programs, economic development, urban planning, mobility and transportation, tourism, disaster impact analysis, sustainability and resilience.
You can reach the company via email at business@citydata.ai if you’d like to discuss your data needs and use cases. You can also follow the company on Linkedin, Twitter, Facebook, YouTube, and the UniverCity.ai blog to stay updated on the newest innovations in mobility data + Ai.